Paper Mempool
Frontend design for the Mempool manycore system. Root paper for project Terapool.
Paper: Mempool
Abstract
This paper demonstrates that it is possible to scale up the shared-L1 architecture. All the cores share a global view of the L1 scratchpad memory pool, accessible within at most 5 cycles. #todo Good idea to see the reference paper [7] for the shared-L1 cache architecture.
Terminology
-
Blocking Network: In the presence of a currently established interconnection between a pair of input/output, the arrival of a request for a new interconnection between two arbitrary unused inputs and output may or may not be possible.
- e.g. Omega, Shuffle-Exchange Network(SEN)
- ! [[ Pasted image 20230109213841.png | 300 ]]
-
Rearrangeable Network: Characterized by the property that it is always possible to rearrange already established connections to make allowance for other connections to be established simultaneously.
- e.g. Benes
- Non-blocking interconnection: Characterized by the property that in the presence of a currently established connection between any pair of input/output, it will always be possible to establish a connection between any arbitrary unused pair of input/output.
- Oblivious Routing: #todo What is oblivious routing
Architecture
Mempool has a shared multi-banked pool of L1 memory, among all 256 cores.
Basic Interconnect
- Two parallel interconnects:
- Core –(request)–> SPM
- SPM –(response)-> Core
- Basic topology: 16 ${\times}$ 16 radix-4 butterfly Main Interconnect Reference
- ! [[ Pasted_image_20230112133043.png | 300 ]]
Core
- ! [[ Pasted_image_20230112133043.png | 300 ]]
-
[[ Snitch ]]: A 21 kGE single-issue single-stage RISC-V-based RV32IMA core, supporting a configurable number of outstanding load instructions, which is useful to hide the SPM access latency.
#todo Further Reading
#todo How to hide SPM access latency
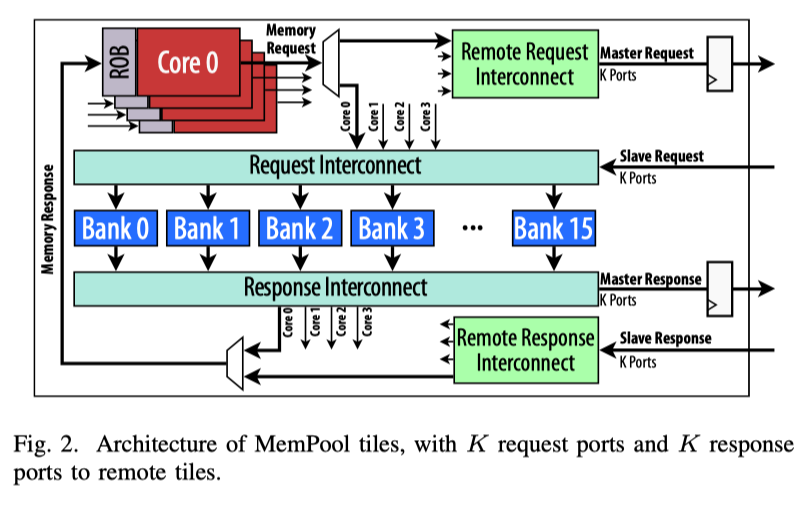
Tile
- 4 [[ Snitch ]] cores, and 16 [[ SPM ]] memory banks.
- Internally: Each core has a dedicated port to access them with 1 cycle latency (Latency source: ROB) #todo Confirm the latency source.
- Externally: Each tile shares K Master request and K slave response ports.
- ! [[ Pasted_image_20230112134313.png | 400 ]]
Group (Hierarchical approach)
- $Top_H$ Each group contains 16 tiles
- Core –> Remote memory bank (same group): 3 cycles latency (Latency source: Master Request Register -> Master Response Register -> ROB)
- Interconnections:
- Internally: Local(L) interconnection: 16 $\times$ 16 radix-4 fully-connected crossbar
- Externally: North(N), Northeast(NE), and East(E) interconnection. 16 $\times$ 16 radix-4 butterfly network. A register boundary at the groups’ master interface. ^MasterGroupRegister
- Inside each tile: a 4 $\times$ 4 crossbar routes the request to each port (L, N, NE, and E).
- ! [[ Pasted_image_20230112135805.png | 300 ]]
Cluster
The cluster is the top level of the Mempool architecture. A cluster contains 4 groups. Core –> Remote memory bank (Remote groups): 5 cycles latency. (Latency source: Tile Master Request Register -> [[ Paper Mempool#^MasterGroupRegister | Group Master Request Register ]] -> Tile Master Response Register -> Group Master Response Register -> ROB). ! [[ Pasted image 20230112140349.png | 200 ]]
Summary
- Latency | Type | Cycles | | —- | —- | | Inter-tile | 1 | | Remote-tile Inter-group | 3 | | Remote-tile Remote-group | 5 |